Unlocking Growth: Data Driven Strategies for Bike-Sharing Success
Body:
The bike-sharing industry thrives on attracting casual riders, but true profitability lies in converting them to loyal annual members. This project tackles this challenge by leveraging data analysis to identify key differentiators between these customer segments.
Key Objectives:
Maximize Profitability: Identify which customer segment (casual riders vs. annual members) offers a more sustainable growth strategy for the company.
Targeted Marketing: Uncover the motivations driving casual riders towards annual memberships, informing data-driven marketing tactics on digital platforms.
Unlocking Member Value: Analyze usage patterns to quantify the convenience and cost-saving benefits of annual memberships for frequent riders.
Data-Driven Insights:
This project utilized a robust data pipeline, encompassing:
Excel: Cleaned and structured a massive dataset (1 million+ rows) by addressing null values, creating new columns, and leveraging Power Query for efficient data manipulation.
SQL (Google BigQuery): Performed deeper analysis on the large dataset to identify trends and answer specific research questions related to cost-savings, convenience, and targeted customer segmentation.
R Programming: Unveiled key differences between casual and annual riders through data visualization, calculated columns, and targeted data manipulation.
Outcomes:
This data-driven approach yielded valuable insights for the bike-sharing company, enabling them to:
Craft Targeted Marketing Campaigns: Leverage digital advertising platforms to reach specific customer segments with personalized messaging based on their needs and location.
Optimize Membership Value Proposition: Quantify the cost savings and convenience benefits of annual memberships to incentivize casual riders toward conversion.
Inform Strategic Decision Making: Guide future growth strategies based on data-backed insights into customer behavior and profitability.
To illustrate the data cleaning process, the following figures depict the initial state of the dataset and the subsequently developed custom function. This function offers the advantage of being reusable across various data quality issues, including empty strings and non-printing characters.


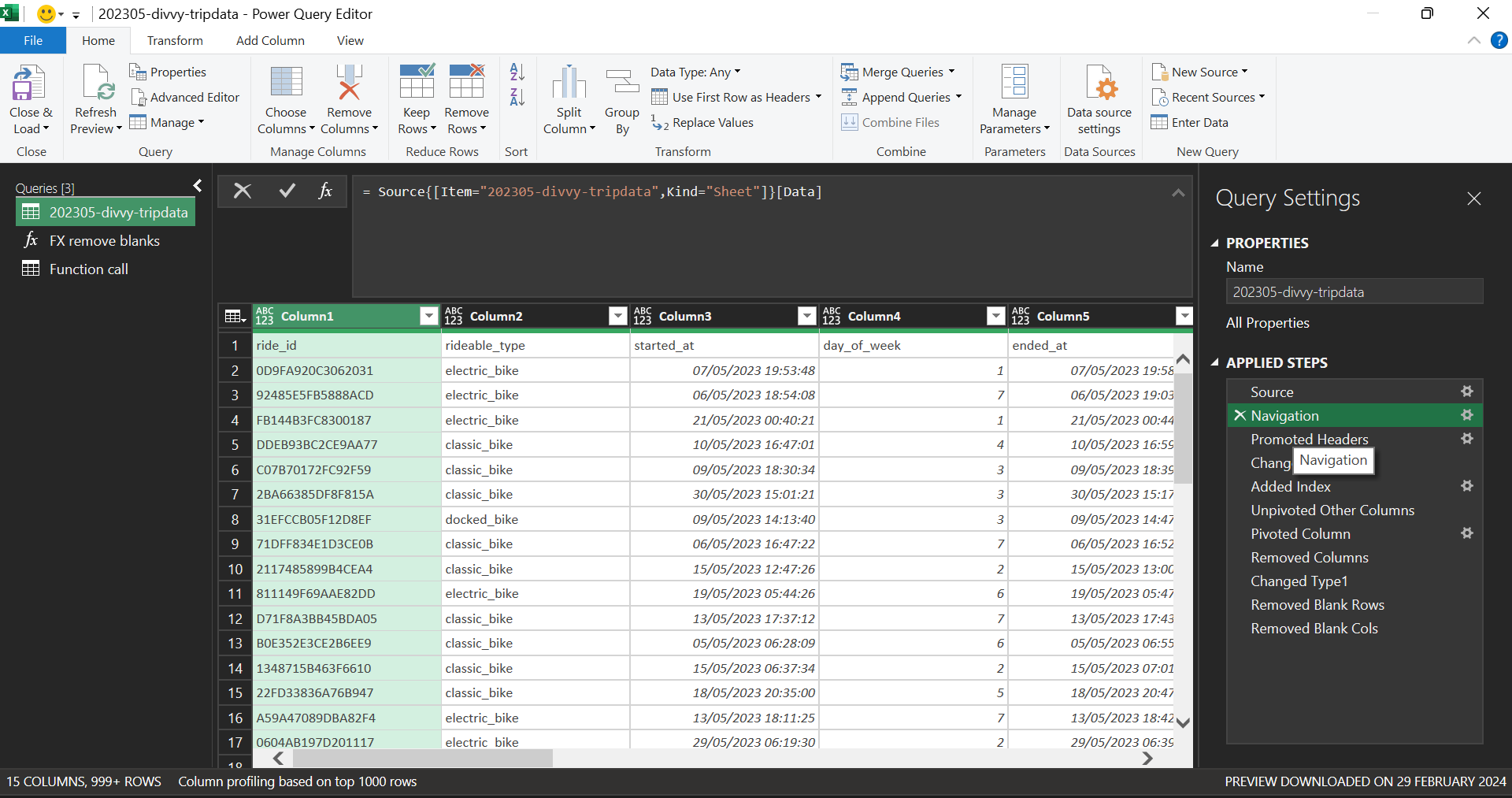
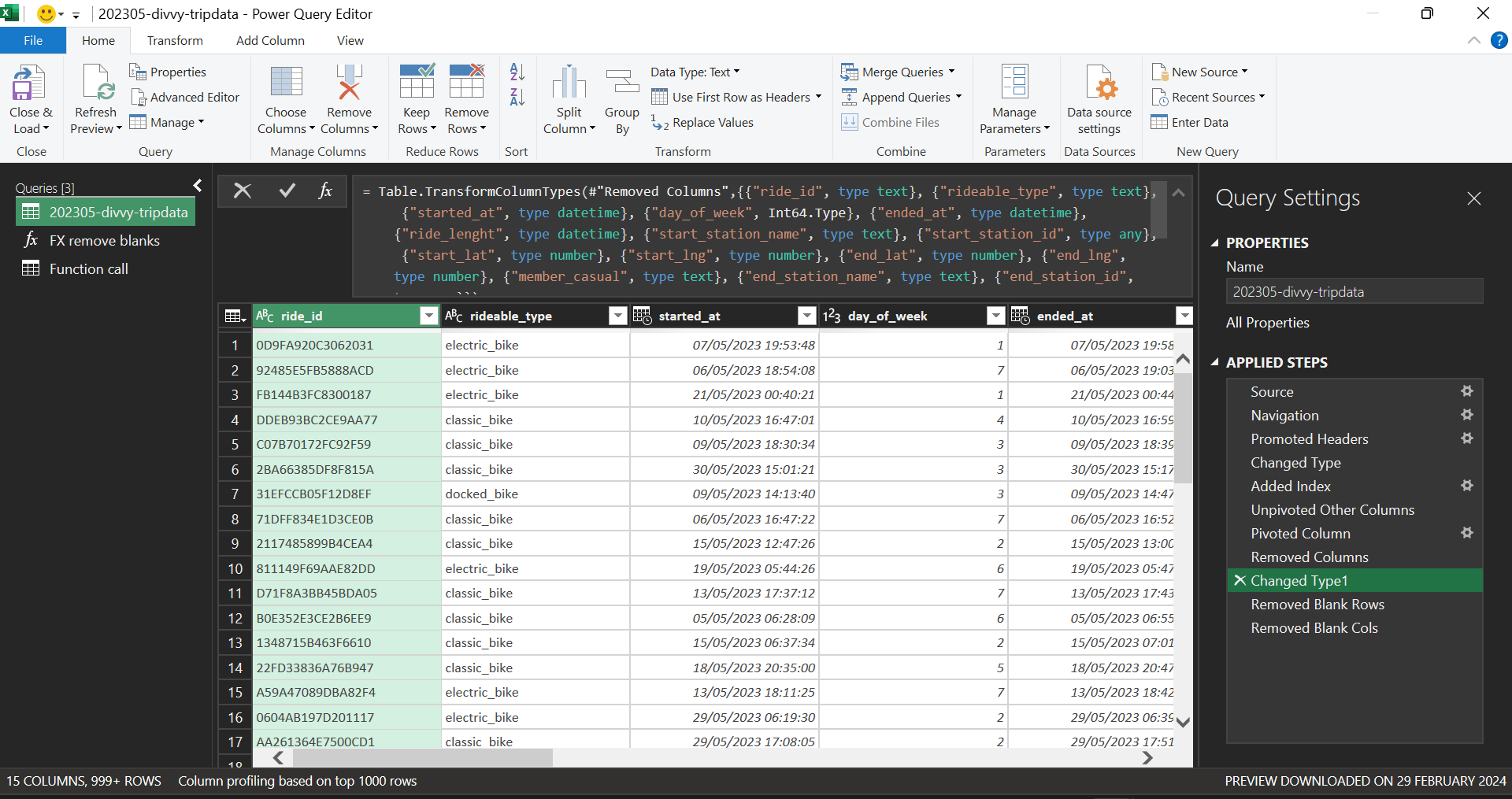

ADVANCED EXCEL FUNCTIONS
“While existing data cleaning tools can address null or blank values in rows and columns, this approach offers a more versatile alternative. We propose a custom function that can be repeatedly invoked to handle a wider range of data quality issues, including empty strings and non-printing characters. This function provides a reusable solution for data cleansing tasks.”
Short clip showcasing power query.
Limitations of Excel for In-Depth Data Analysis:
While Excel remains a valuable tool for initial data exploration and basic manipulation, its capabilities become increasingly limited as the data size and complexity grow:
Performance Bottlenecks: Excel's processing power struggles with massive datasets (over 1 million rows). This can lead to slow performance, hindering efficient data manipulation and analysis.
Limited Data Cleaning Capabilities: Excel's data cleaning functionalities are primarily manual, making it cumbersome to address complex data quality issues like null values, inconsistencies, and duplicates in large datasets.
Inability to Answer Advanced Research Questions: Excel's analytical capabilities are restricted. It may not provide the necessary functionalities to answer intricate research questions that require advanced statistical modeling, data mining techniques, or complex data transformations.
Limited Data Visualization: Excel's visualization tools offer basic functionality, but they may not be sufficient for creating compelling and interactive visualizations that effectively communicate complex insights from large datasets.
Granular Data Manipulation Challenges: While Excel allows for basic data manipulation like filtering and sorting, it can be cumbersome and error-prone for intricate tasks like dropping multiple irrelevant columns, creating new dataframes with specific structures, or efficiently modifying complex data structures.